
Text Embeddings (2/3) - Computation
Introduction
This is the second of three articles on text embeddings for beginners:
- Text Embeddings (1/3) - Explanation
- Text Embeddings (2/3) - Computation (you are here)
- Text Embeddings (3/3) - Conclusion
Here you may find several ways of how to compute text embeddings with code samples.
Computing Text Embeddings
Here are described several methods of how text embeddings can be computed:
- Word Embeddings
- Zero-Shot Classification
- Text Classification
- Sentence Transformers
- OpenAI Embeddings
Before we begin
Below I will be using a function plot_heatmap to show you
how different texts are similar to each other in the embeddings space.
Here is its source code:
Note: you need to install the matplotlib and numpy Python libraries.
But I am absolutely sure you already have them installed ;)
from typing import Optional, Sequence, Union
import numpy as np
def plot_heatmap(m: np.ndarray,
title: Optional[str] = None,
cmap: str = 'winter',
aspect: Union[str, float] = 'auto',
x_labels: Optional[Sequence[str]] = None,
y_labels: Optional[Sequence[str]] = None,
**kwargs):
import matplotlib.pyplot as plt
import matplotlib.patheffects as pef
# Initialize figure
fig, ax = plt.subplots(**kwargs)
im = ax.imshow(m, cmap=cmap, aspect=aspect)
# Show all ticks and label them with the respective list entries
x_labels = x_labels or list(range(m.shape[1]))
y_labels = y_labels or list(range(m.shape[0]))
ax.set_xticks(np.arange(m.shape[1]), labels=x_labels, rotation=45, ha='right')
ax.set_yticks(np.arange(m.shape[0]), labels=y_labels)
# Loop over data dimensions and create text annotations.
for i in range(m.shape[0]):
for j in range(m.shape[1]):
text = ax.text(j, i, m[i, j], ha='center', va='center', color='white')
text.set_path_effects([pef.withStroke(linewidth=1, foreground='black')])
if title is not None:
ax.set_title(title)
fig.tight_layout()
plt.show()
1. Word Embeddings
Description
Since 2010 algorithms like Word2Vec and GloVe introduced new concept: Word Embeddings.
This is a representation of words as dense vectors in a continuous vector space, capturing semantic relationships. This allowed for more nuanced text comparisons.
The simplest solution to compute text embedding is to take the mean value over all of its words:
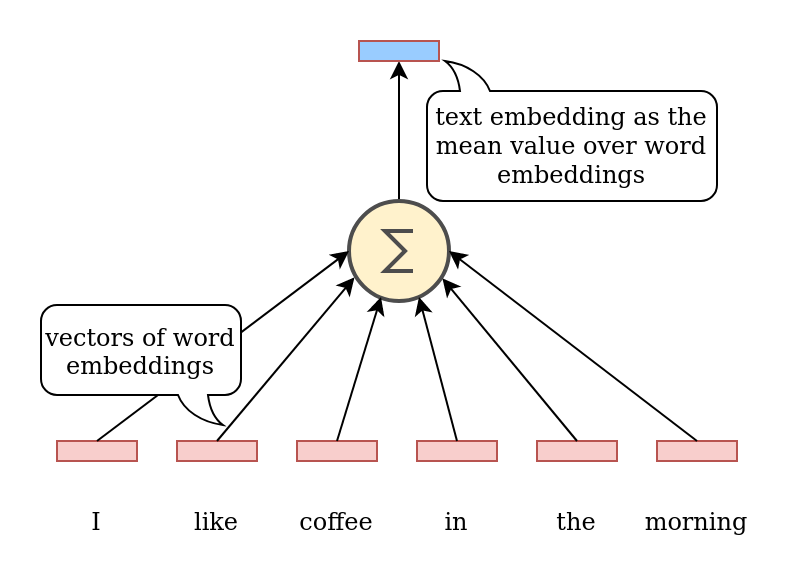
Computation
You need to install the gensim, numpy and scikit-learn Python libraries.
It gives you access to many pre-trained word embeddings dictionaries:
fasttext-wiki-news-subwords-300conceptnet-numberbatch-17-06-300word2vec-ruscorpora-300word2vec-google-news-300glove-wiki-gigaword-50glove-wiki-gigaword-100glove-wiki-gigaword-200glove-wiki-gigaword-300glove-twitter-25glove-twitter-50glove-twitter-100glove-twitter-200
In the following example I am going to use the fasttext-wiki-news-subwords-300 dictionary.
import string
import gensim
import gensim.downloader
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
model_name = 'fasttext-wiki-news-subwords-300'
model = gensim.downloader.load(model_name)
def words_embeddings(text: str) -> np.ndarray:
"""Return text embedding as the mean value of its words embeddings"""
if isinstance(text, str):
for c in string.punctuation:
text = text.replace(c, ' ')
text = text.lower().split()
return model.get_mean_vector(text)
texts = {
'Thermos Ads': 'Introducing the Adventure Thermos – your ideal companion for outdoor excursions! Engineered for durability and optimum insulation, this thermos keeps your beverages hot or cold in any terrain. Whether you’re hiking, camping, or simply enjoying the great outdoors, trust PeakPro to keep your drinks at the perfect temperature throughout your adventure. Upgrade your outdoor experience with the Adventure Thermos – where every sip is an exploration in refreshment.',
'How to become an Uber driver': 'Embark on a flexible and rewarding journey by becoming an Uber driver today! Getting started is easy – simply visit the Uber website or download the app to begin your driver application. Provide the required documents, including a valid driver’s license, insurance, and vehicle registration, and undergo a straightforward background check. Once approved, you’re ready to hit the road, set your own schedule, and earn money on your terms. Join the community of Uber drivers and turn your car into a source of income and independence.',
'Crypto vs S&P500': 'Amidst a correction in the S&P index, the cryptocurrency market remains remarkably stable, showcasing its resilience in the face of traditional market fluctuations. Investors find solace in the consistent performance of cryptocurrencies, highlighting their potential as a diversification strategy. As the S&P undergoes correction, the crypto market’s steadiness prompts a reevaluation of investment portfolios in the ever-evolving financial landscape.',
'Used boots for sale': 'For sale: Gently-used rubber boots in excellent condition! These reliable boots are ready for their next adventure, offering comfort and durability. Don’t miss the chance to snag a great pair at a fantastic price!',
'EU central bank fights inflation': 'In a bold move to tackle inflationary pressures, the European Union’s central bank has announced an increase in its key interest rate. This strategic measure aims to curb rising inflation and maintain economic stability within the EU. Investors and economists will closely monitor the impacts of this decision on financial markets and the broader economic landscape.',
'VW tries to resurrect the Bus': 'Volkswagen is making waves with the revival of the iconic VW Bus, now featuring a state-of-the-art electric engine. Combining nostalgia with environmental consciousness, the electric VW Bus aims to redefine road-tripping for the modern era. Get ready to experience the classic charm of the VW Bus with a sustainable twist, as Volkswagen pioneers a new chapter in electric mobility.',
}
names = list(texts.keys())
embeddings = [words_embeddings(text) for text in texts.values()]
similarities = cosine_similarity(embeddings)
plot_heatmap(similarities.round(3), title='Words Embeddings Method', aspect=0.5, x_labels=names, y_labels=names, figsize=(8, 8))
The exact values of embedding are not interesting. Because they are not interpretable. I.e.: we do not know what a particular dimension mean.
Instead, I plot the similarity matrix of texts:
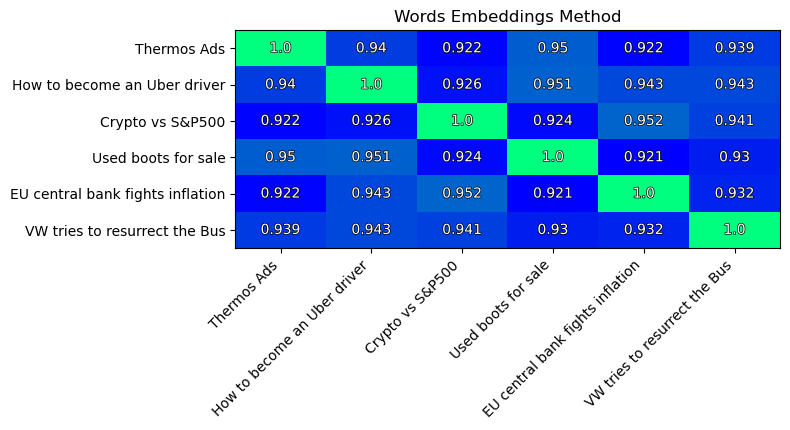
Note: Cosine similarity values occupy the range: [-1, 1]. Where -1 means
vectors ape opposite to each other, 0 meansvectors are perpendecular, and 1 meansvectors are oriented in the same direction.
Note the pair of most similar texts (similarity=0.952):
- “Crypto vs S&P500”
- “EU central bank fights inflation”
This result is expected.
On the second place we have two texts (similarity=0.951):
- “Used boots for sale”
- “How to become an Uber driver”
This does not make any sense!
As you can see, the variance in similarities is small.
All similarities are close to: 0.9.
This means the method is not very good to distinguish and compare texts.
“One more thing” (c).
I want to perform a simple negation test.
test = [
'I like coffee',
'I abstain from coffee',
'I do not like coffee',
'I hate coffee',
]
embeddings = [words_embeddings(text) for text in test]
similarities = cosine_similarity(embeddings)
plot_heatmap(similarities.round(3), title='Words Embeddings Method - Negation Test', x_labels=test, y_labels=test, figsize=(8, 8))
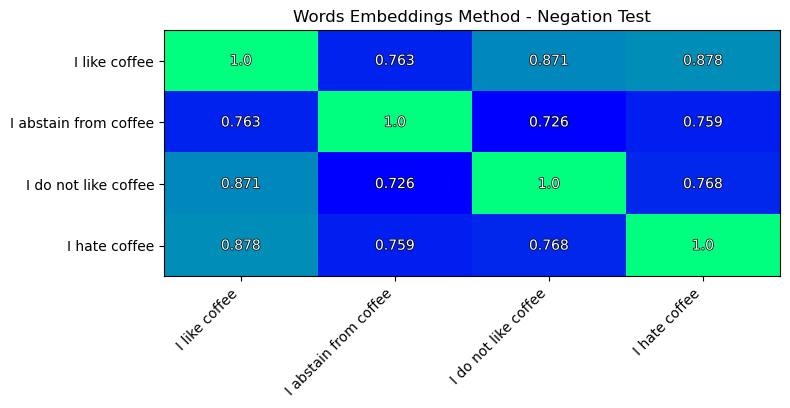
The result is very disappointing.
As I like coffee and I hate coffee are closer to each other than
I do no like coffee and I hate coffee. This contradicts to out logic.
Pros and Cons
This is the easiest and fastest solution. You only need to have a dictionary of pre-trained words embeddings. Such dictionaries are freely available.
Nevertheless, this method does not take into account the contextual relationships between words in a sentence. As a result, all texts look similar to each other in the embeddings space.
Additionally, this method fails the simple negation test.
2. Zero-Shot Classification
Description
There is a field in machine learning called Natural Language Inference (NLI). This field is focused on models, which can compare two texts: a hypothesis and premise - and answer whether a hypothesis is True (entailment), False (contradiction), or Undetermined (neutral) for a given premise.
We can take out input text as premise and each of the categories as hypothesis. Then we can compute the probabilities of a pair and take the entailnment probability as the measurement of a text across a category.
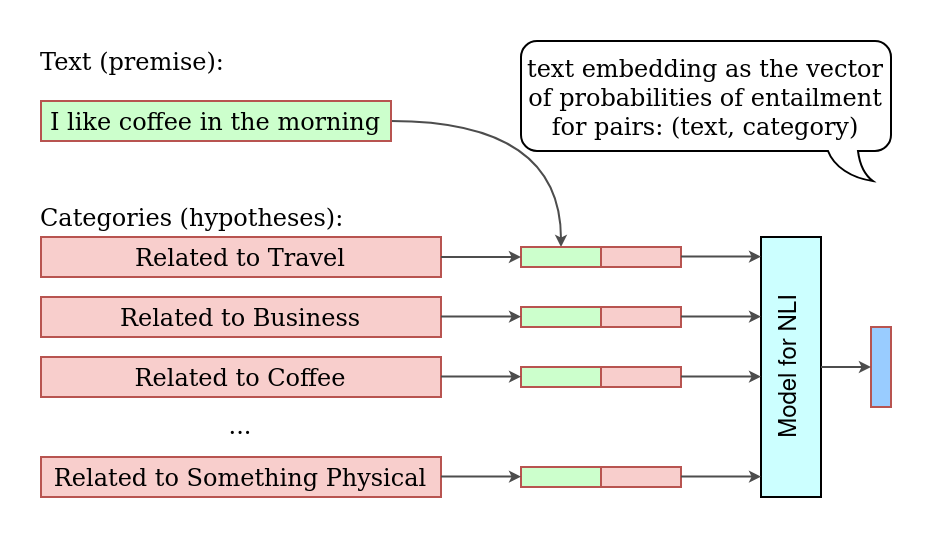
Computation
Lets use the following model for zero-shot classification: MoritzLaurer/multilingual-MiniLMv2-L6-mnli-xnli.
To run this code you need to install the transformers, pandas and scikit-learn libraries.
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from sklearn.metrics.pairwise import cosine_similarity
from typing import Union, Sequence
import pandas as pd
import numpy as np
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model_name = 'MoritzLaurer/multilingual-MiniLMv2-L6-mnli-xnli'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name).to(device)
classes = "Advertisement,Arts,Auto,Beauty,Business,College,Comedy,Crime,Culture,Economics,Education,Entertainment,Environment,Finance,Food & Drink,Good News,Green,Health,Home & Living,Impact,Media,Money,News,Parenting,Politics,Religion,Science,Sports,Style,Taste,Tech,Tourism,Travel,Weddings,Weird News,Wellness,Women,World News".split(',')
print(f'Have: {len(classes)} classes in total')
texts = {
'Thermos Ads': 'Introducing the Adventure Thermos – your ideal companion for outdoor excursions! Engineered for durability and optimum insulation, this thermos keeps your beverages hot or cold in any terrain. Whether you’re hiking, camping, or simply enjoying the great outdoors, trust PeakPro to keep your drinks at the perfect temperature throughout your adventure. Upgrade your outdoor experience with the Adventure Thermos – where every sip is an exploration in refreshment.',
'How to become an Uber driver': 'Embark on a flexible and rewarding journey by becoming an Uber driver today! Getting started is easy – simply visit the Uber website or download the app to begin your driver application. Provide the required documents, including a valid driver’s license, insurance, and vehicle registration, and undergo a straightforward background check. Once approved, you’re ready to hit the road, set your own schedule, and earn money on your terms. Join the community of Uber drivers and turn your car into a source of income and independence.',
'Crypto vs S&P500': 'Amidst a correction in the S&P index, the cryptocurrency market remains remarkably stable, showcasing its resilience in the face of traditional market fluctuations. Investors find solace in the consistent performance of cryptocurrencies, highlighting their potential as a diversification strategy. As the S&P undergoes correction, the crypto market’s steadiness prompts a reevaluation of investment portfolios in the ever-evolving financial landscape.',
'Used boots for sale': 'For sale: Gently-used rubber boots in excellent condition! These reliable boots are ready for their next adventure, offering comfort and durability. Don’t miss the chance to snag a great pair at a fantastic price!',
'EU central bank fights inflation': 'In a bold move to tackle inflationary pressures, the European Union’s central bank has announced an increase in its key interest rate. This strategic measure aims to curb rising inflation and maintain economic stability within the EU. Investors and economists will closely monitor the impacts of this decision on financial markets and the broader economic landscape.',
'VW tries to resurrect the Bus': 'Volkswagen is making waves with the revival of the iconic VW Bus, now featuring a state-of-the-art electric engine. Combining nostalgia with environmental consciousness, the electric VW Bus aims to redefine road-tripping for the modern era. Get ready to experience the classic charm of the VW Bus with a sustainable twist, as Volkswagen pioneers a new chapter in electric mobility.',
}
def zeroshot_embedding(premise: str, hypothesis: Union[str, Sequence[str]]) -> np.ndarray:
# Tokenize the input text pairs
assert isinstance(premise, str)
if isinstance(hypothesis, str):
hypothesis = [hypothesis]
premise = [premise] * len(hypothesis)
inputs = tokenizer(premise, hypothesis, return_tensors='pt', truncation=True, max_length=512, padding='max_length').to(device)
# Compute class probabilities for (entailnment, neutral, contradiction)
with torch.no_grad():
logits = model(**inputs)[0]
class_probabilities = torch.softmax(logits, dim=-1).cpu().numpy()
class_probabilities = class_probabilities[..., 0] # Take only the entailnment probability
return class_probabilities
df = pd.DataFrame([], columns=classes, index=[])
for caption, text in texts.items():
class_probabilities = zeroshot_embedding(text, classes)
df.loc[caption] = class_probabilities
print(df.idxmax(axis=1))
print(df.round(4).to_markdown())
similarities = cosine_similarity(df.values)
names = list(texts.keys())
plot_heatmap(similarities.round(3), title='Zero-Shot Classification Method', aspect=0.4, x_labels=names, y_labels=names, figsize=(8, 8))
Have: 38 classes in total
Thermos Ads Food & Drink
How to become an Uber driver Advertisement
Crypto vs S&P500 Advertisement
Used boots for sale Advertisement
EU central bank fights inflation Politics
VW tries to resurrect the Bus Advertisement
| Text | Advertisement | Arts | Auto | Beauty | Business | College | Comedy | Crime | Culture | Economics | Education | Entertainment | Environment | Finance | Food & Drink | Good News | Green | Health | Home & Living | Impact | Media | Money | News | Parenting | Politics | Religion | Science | Sports | Style | Taste | Tech | Tourism | Travel | Weddings | Weird News | Wellness | Women | World News |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Thermos Ads | 0.0671 | 0.0308 | 0.0336 | 0.0322 | 0.0305 | 0.0254 | 0.0316 | 0.0313 | 0.0375 | 0.0224 | 0.0374 | 0.0518 | 0.0528 | 0.0252 | 0.1636 | 0.0381 | 0.0223 | 0.0316 | 0.0791 | 0.0456 | 0.0343 | 0.0329 | 0.0304 | 0.0391 | 0.0302 | 0.0265 | 0.0288 | 0.0333 | 0.0423 | 0.0393 | 0.0331 | 0.0389 | 0.0465 | 0.0347 | 0.0214 | 0.0390 | 0.0254 | 0.0278 |
| How to become an Uber driver | 0.3571 | 0.1689 | 0.1912 | 0.1163 | 0.1716 | 0.1343 | 0.1743 | 0.0800 | 0.1518 | 0.1060 | 0.1546 | 0.1772 | 0.2145 | 0.1698 | 0.0451 | 0.1751 | 0.1536 | 0.1251 | 0.1444 | 0.2439 | 0.2033 | 0.3217 | 0.1848 | 0.1486 | 0.1233 | 0.0864 | 0.1282 | 0.1196 | 0.2127 | 0.2450 | 0.1570 | 0.1002 | 0.2705 | 0.0864 | 0.0495 | 0.1541 | 0.0986 | 0.1042 |
| Crypto vs S&P500 | 0.2528 | 0.0936 | 0.1147 | 0.0506 | 0.0549 | 0.0618 | 0.1009 | 0.0598 | 0.0717 | 0.0469 | 0.0403 | 0.0502 | 0.1089 | 0.0679 | 0.0060 | 0.0696 | 0.0632 | 0.0325 | 0.0221 | 0.1979 | 0.1121 | 0.0929 | 0.1217 | 0.0235 | 0.0483 | 0.0328 | 0.0682 | 0.0529 | 0.1475 | 0.1246 | 0.0850 | 0.0185 | 0.0341 | 0.0206 | 0.0276 | 0.0847 | 0.0260 | 0.0410 |
| Used boots for sale | 0.5045 | 0.0430 | 0.0564 | 0.0842 | 0.0527 | 0.0311 | 0.0154 | 0.0250 | 0.0959 | 0.0209 | 0.0525 | 0.2897 | 0.2669 | 0.0331 | 0.3168 | 0.1004 | 0.0353 | 0.0893 | 0.0747 | 0.1783 | 0.0431 | 0.1089 | 0.0295 | 0.0916 | 0.0288 | 0.0102 | 0.0207 | 0.1112 | 0.3576 | 0.1675 | 0.0469 | 0.0622 | 0.1675 | 0.0888 | 0.0615 | 0.0906 | 0.1818 | 0.0112 |
| EU central bank fights inflation | 0.0592 | 0.0055 | 0.0077 | 0.0066 | 0.0090 | 0.0063 | 0.0106 | 0.0073 | 0.0076 | 0.0743 | 0.0049 | 0.0061 | 0.0777 | 0.0122 | 0.0015 | 0.0225 | 0.0081 | 0.0035 | 0.0092 | 0.0662 | 0.0085 | 0.0136 | 0.0078 | 0.0024 | 0.1194 | 0.0037 | 0.0071 | 0.0066 | 0.0111 | 0.0207 | 0.0079 | 0.0020 | 0.0040 | 0.0037 | 0.0108 | 0.0099 | 0.0051 | 0.0083 |
| VW tries to resurrect the Bus | 0.3772 | 0.3122 | 0.2554 | 0.1225 | 0.1652 | 0.1197 | 0.1381 | 0.1072 | 0.2291 | 0.1302 | 0.1730 | 0.2965 | 0.2283 | 0.1300 | 0.0645 | 0.1673 | 0.1314 | 0.1313 | 0.1310 | 0.3150 | 0.2098 | 0.1638 | 0.2000 | 0.1107 | 0.1243 | 0.0880 | 0.1645 | 0.1596 | 0.2972 | 0.2203 | 0.1733 | 0.1177 | 0.2383 | 0.0740 | 0.0585 | 0.1219 | 0.0770 | 0.0970 |
The similarity matrix of texts:
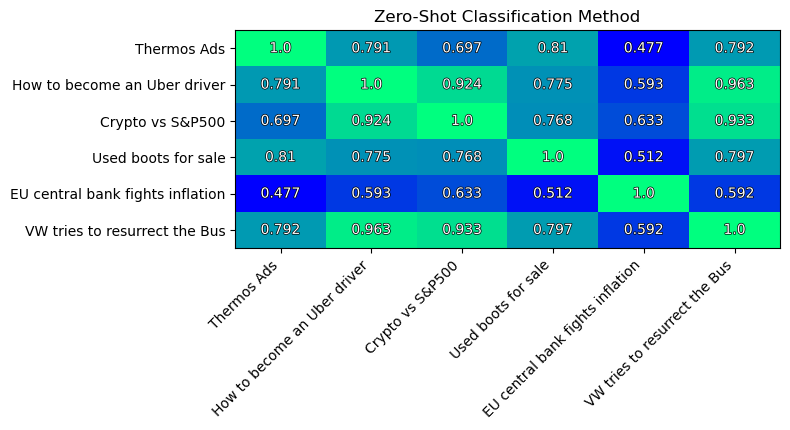
In general, the results are ok. Yet I consider the computed top-classes for each text are not good. I believe, this is due to the selected model, not due to the method itself.
Note the pair of most similar texts (similarity=0.963):
- “How to become an Uber driver”
- “VW tries to resurrect the Bus”
This is ok.
And on the second place we have the pair of texts (similarity=0.933):
- “Crypto vs S&P500”
- “VW tries to resurrect the Bus”
This is not ok.
What I do not like about the results is that numbers are still close to each other: ~ 0.9. This method fails to grasp differences in texts.
The simple negation test:
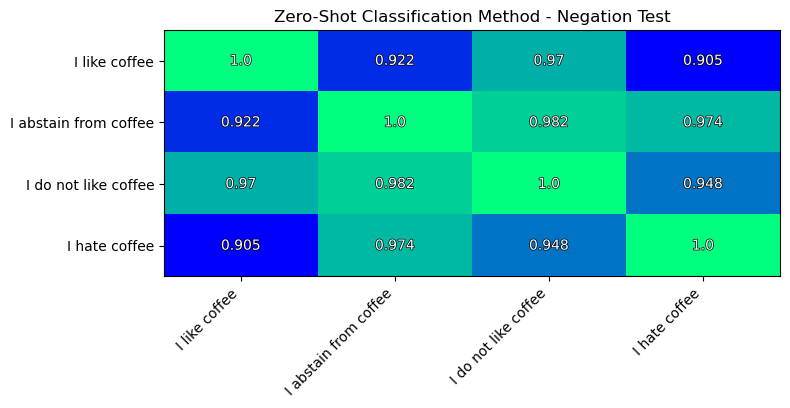
The negation test results are slightly better than of the previous method. But still not as I would expect them to be.
Pros and Cons
Experiments show that embeddings produced this can be used for the task of text comparison.
This approach has the benefit as the dimensions of an embedding vector are interpretable. I.e. each dimension corresponds to some category. Also, we can easily adjust the list of categories (by recomputing, of course).
The drawback here is that it takes too much time to compute embedding of a text this way. It may take up to minute to compute embedding for a text on a server with GPU! This method is not practical.
Additionally, this method does not grasp differences between texts very well. And it is not good at the simple negation test.
3. Text Classification
Description
The task of text classification is as easy as it sounds: given a text we somehow assign one of pre-defined labels to it.
In the simplest case of Sentiment Analysis
there are only two classes: positive and negative. Sentiment Analysis is used, for example,
to compute the Bitcoin Sentiment
or to programmatically find negative comments about some company in a social network.
Of course, any number of classes can be used. As it has been described earlier, the more numbers we have - the better we can describe a text.
For example lets have a look at the model cssupport/bert-news-class. It is trained to categorize text for 41 classes:
| Classes | Classes | Classes | Classes | Classes | Classes |
|---|---|---|---|---|---|
| Arts | Culture & Arts | Green | Parenting | Style | Weddings |
| Arts & Culture | Education | Healthy Living | Parents | Style & Beauty | Weird News |
| Black Voices | Entertainment | Home & Living | Politics | Taste | Wellness |
| Business | Environment | Impact | Queer Voices | Tech | Women |
| College | Fifty | Latino Voices | Religion | The Worldpost | World News |
| Comedy | Food & Drink | Media | Science | Travel | Worldpost |
| Crime | Good News | Money | Sports | U.S. News |
This particular model is a fine-tuned version of bert-base-uncased model under the hood.
BERT is acronym for: Bidirectional Encoder Representations from Transformers. Today BERT-based models are the de facto standard for text classification tasks.
A text in such model is processed in multiple stages:
- First text is tokenized (split into words or parts or words).
- Special tokens
[CLS]and[SEP]are added to the text. - Each token is substituted by corresponding token embedding using a pre-trained table.
- Those token embeddings are passed into the model.
- The information passes through multiple Transformer Encoder layers, and is processed in each layer.
- At the output of a final layer only the first computed value, at the position of the
[CLS]token, is used. - It is passed into a small classifier network, which computes the final probabilities for the required classes.
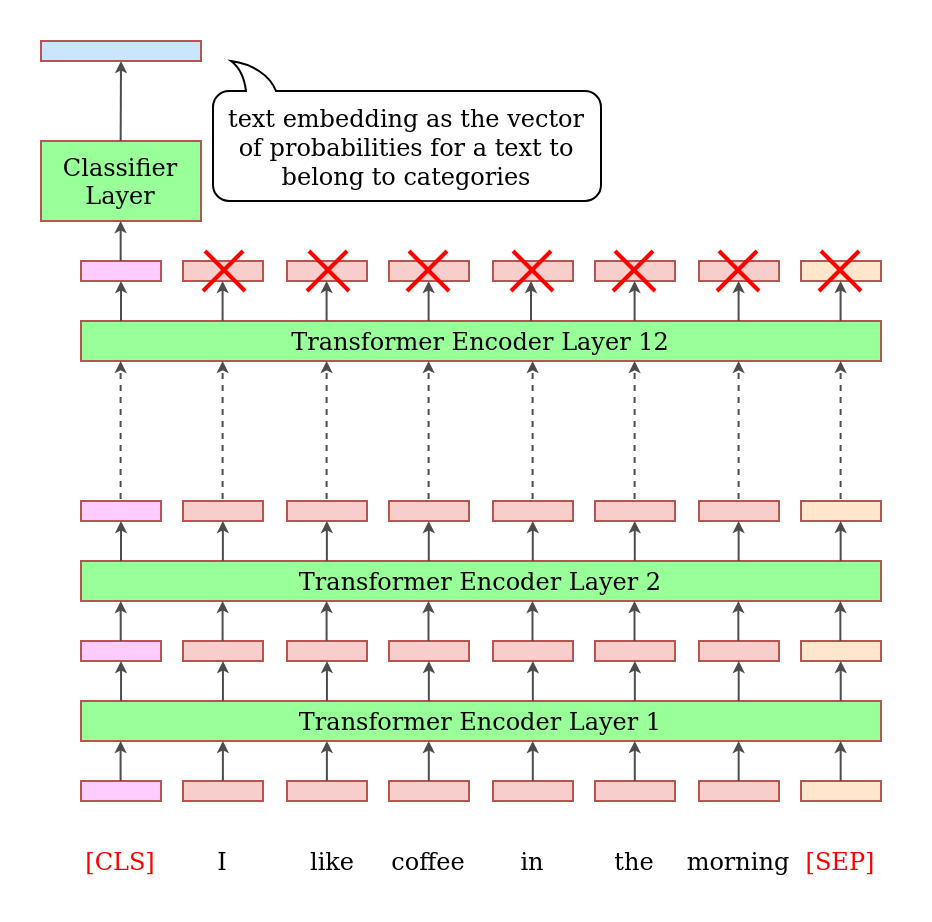
The model outputs 41 numbers - these are the probabilities that a text belongs to a certain category. Typically, the category with the highest probability is taken as the final outcome. But in our task we would instead keep all 41 numbers as the text embedding.
Computation
To run the following code you need to install the transformers, pandas and scikit-learn Python libraries.
Here is the source code of how to compute such text embeddings:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from sklearn.metrics.pairwise import cosine_similarity
from typing import Union, Sequence, List
import pandas as pd
import numpy as np
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model_name = 'cssupport/bert-news-class'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name).to(device)
classes = "Arts,Arts & Culture,Black Voices,Business,College,Comedy,Crime,Culture & Arts,Education,Entertainment,Environment,Fifty,Food & Drink,Good News,Green,Healthy Living,Home & Living,Impact,Latino Voices,Media,Money,Parenting,Parents,Politics,Queer Voices,Religion,Science,Sports,Style,Style & Beauty,Taste,Tech,The Worldpost,Travel,U.S. News,Weddings,Weird News,Wellness,Women,World News,Worldpost".split(',')
print(f'Have: {len(classes)} classes in total')
texts = {
'Thermos Ads': 'Introducing the Adventure Thermos – your ideal companion for outdoor excursions! Engineered for durability and optimum insulation, this thermos keeps your beverages hot or cold in any terrain. Whether you’re hiking, camping, or simply enjoying the great outdoors, trust PeakPro to keep your drinks at the perfect temperature throughout your adventure. Upgrade your outdoor experience with the Adventure Thermos – where every sip is an exploration in refreshment.',
'How to become an Uber driver': 'Embark on a flexible and rewarding journey by becoming an Uber driver today! Getting started is easy – simply visit the Uber website or download the app to begin your driver application. Provide the required documents, including a valid driver’s license, insurance, and vehicle registration, and undergo a straightforward background check. Once approved, you’re ready to hit the road, set your own schedule, and earn money on your terms. Join the community of Uber drivers and turn your car into a source of income and independence.',
'Crypto vs S&P500': 'Amidst a correction in the S&P index, the cryptocurrency market remains remarkably stable, showcasing its resilience in the face of traditional market fluctuations. Investors find solace in the consistent performance of cryptocurrencies, highlighting their potential as a diversification strategy. As the S&P undergoes correction, the crypto market’s steadiness prompts a reevaluation of investment portfolios in the ever-evolving financial landscape.',
'Used boots for sale': 'For sale: Gently-used rubber boots in excellent condition! These reliable boots are ready for their next adventure, offering comfort and durability. Don’t miss the chance to snag a great pair at a fantastic price!',
'EU central bank fights inflation': 'In a bold move to tackle inflationary pressures, the European Union’s central bank has announced an increase in its key interest rate. This strategic measure aims to curb rising inflation and maintain economic stability within the EU. Investors and economists will closely monitor the impacts of this decision on financial markets and the broader economic landscape.',
'VW tries to resurrect the Bus': 'Volkswagen is making waves with the revival of the iconic VW Bus, now featuring a state-of-the-art electric engine. Combining nostalgia with environmental consciousness, the electric VW Bus aims to redefine road-tripping for the modern era. Get ready to experience the classic charm of the VW Bus with a sustainable twist, as Volkswagen pioneers a new chapter in electric mobility.',
}
def classifier_embeddings(text: Union[str, Sequence[str]]) -> np.ndarray:
"""Compute embeddings with text classification method"""
input_is_string = isinstance(text, str)
# Tokenize the input text
inputs = tokenizer(text, return_tensors='pt', truncation=True, max_length=512, padding='max_length').to(device)
# Compute class probabilities
with torch.no_grad():
logits = model(**inputs)[0]
class_probabilities = torch.softmax(logits, dim=-1).cpu().numpy()
if input_is_string:
return class_probabilities[0]
return class_probabilities
class_probabilities = classifier_embeddings(list(texts.values()))
names = list(texts.keys())
df = pd.DataFrame(class_probabilities, columns=classes, index=names)
print(df.idxmax(axis=1))
print(df.round(4).to_markdown())
similarities = cosine_similarity(class_probabilities)
plot_heatmap(similarities.round(3), title='Text Classification Method', aspect=0.4, x_labels=names, y_labels=names, figsize=(8, 8))
The most probable category for each text:
Have: 41 classes in total
Thermos Ads Travel
How to become an Uber driver Business
Crypto vs S&P500 Business
Used boots for sale Style
EU central bank fights inflation Business
VW tries to resurrect the Bus Business
The text embeddings for each text:
| Text | Arts | Arts & Culture | Black Voices | Business | College | Comedy | Crime | Culture & Arts | Education | Entertainment | Environment | Fifty | Food & Drink | Good News | Green | Healthy Living | Home & Living | Impact | Latino Voices | Media | Money | Parenting | Parents | Politics | Queer Voices | Religion | Science | Sports | Style | Style & Beauty | Taste | Tech | The Worldpost | Travel | U.S. News | Weddings | Weird News | Wellness | Women | World News | Worldpost |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Thermos Ads | 0.0040 | 0.0020 | 0.0001 | 0.0104 | 0.0010 | 0.0019 | 0.0006 | 0.0038 | 0.0017 | 0.0003 | 0.0037 | 0.0259 | 0.0094 | 0.0035 | 0.0079 | 0.0116 | 0.0046 | 0.0024 | 0.0008 | 0.0006 | 0.0055 | 0.0027 | 0.0024 | 0.0002 | 0.0011 | 0.0018 | 0.0054 | 0.0007 | 0.0052 | 0.0051 | 0.0230 | 0.0035 | 0.0010 | 0.8289 | 0.0006 | 0.0024 | 0.0043 | 0.0065 | 0.0010 | 0.0008 | 0.0017 |
| How to become an Uber driver | 0.0019 | 0.0014 | 0.0015 | 0.7740 | 0.0070 | 0.0019 | 0.0016 | 0.0013 | 0.0155 | 0.0009 | 0.0012 | 0.0160 | 0.0030 | 0.0025 | 0.0017 | 0.0123 | 0.0034 | 0.0252 | 0.0015 | 0.0021 | 0.0034 | 0.0022 | 0.0070 | 0.0045 | 0.0032 | 0.0017 | 0.0009 | 0.0008 | 0.0019 | 0.0020 | 0.0028 | 0.0647 | 0.0008 | 0.0107 | 0.0024 | 0.0010 | 0.0009 | 0.0019 | 0.0096 | 0.0006 | 0.0011 |
| Crypto vs S&P500 | 0.0006 | 0.0003 | 0.0004 | 0.9250 | 0.0025 | 0.0003 | 0.0011 | 0.0004 | 0.0031 | 0.0008 | 0.0010 | 0.0008 | 0.0013 | 0.0006 | 0.0039 | 0.0020 | 0.0011 | 0.0046 | 0.0004 | 0.0017 | 0.0014 | 0.0004 | 0.0004 | 0.0109 | 0.0003 | 0.0004 | 0.0016 | 0.0006 | 0.0005 | 0.0007 | 0.0011 | 0.0163 | 0.0007 | 0.0016 | 0.0062 | 0.0003 | 0.0006 | 0.0005 | 0.0007 | 0.0008 | 0.0019 |
| Used boots for sale | 0.0100 | 0.0062 | 0.0018 | 0.0081 | 0.0048 | 0.0027 | 0.0018 | 0.0185 | 0.0060 | 0.0020 | 0.0067 | 0.0243 | 0.0300 | 0.0173 | 0.0050 | 0.0074 | 0.0232 | 0.0101 | 0.0015 | 0.0013 | 0.0198 | 0.0109 | 0.0104 | 0.0003 | 0.0052 | 0.0043 | 0.0032 | 0.0099 | 0.4820 | 0.1574 | 0.0197 | 0.0031 | 0.0025 | 0.0189 | 0.0010 | 0.0184 | 0.0161 | 0.0095 | 0.0105 | 0.0025 | 0.0059 |
| EU central bank fights inflation | 0.0074 | 0.0013 | 0.0007 | 0.3497 | 0.0074 | 0.0007 | 0.0025 | 0.0035 | 0.0107 | 0.0042 | 0.0080 | 0.0026 | 0.0089 | 0.0033 | 0.0470 | 0.0082 | 0.0050 | 0.0765 | 0.0036 | 0.0035 | 0.0077 | 0.0025 | 0.0010 | 0.0361 | 0.0007 | 0.0027 | 0.0095 | 0.0022 | 0.0023 | 0.0066 | 0.0067 | 0.0071 | 0.0521 | 0.0085 | 0.0170 | 0.0028 | 0.0016 | 0.0040 | 0.0014 | 0.0825 | 0.1907 |
| VW tries to resurrect the Bus | 0.0030 | 0.0014 | 0.0006 | 0.8037 | 0.0044 | 0.0005 | 0.0012 | 0.0014 | 0.0062 | 0.0008 | 0.0027 | 0.0045 | 0.0036 | 0.0036 | 0.0228 | 0.0041 | 0.0035 | 0.0406 | 0.0010 | 0.0015 | 0.0033 | 0.0010 | 0.0012 | 0.0066 | 0.0005 | 0.0013 | 0.0036 | 0.0010 | 0.0015 | 0.0018 | 0.0027 | 0.0214 | 0.0012 | 0.0254 | 0.0061 | 0.0007 | 0.0018 | 0.0018 | 0.0013 | 0.0012 | 0.0033 |
The similarity matrix of texts:
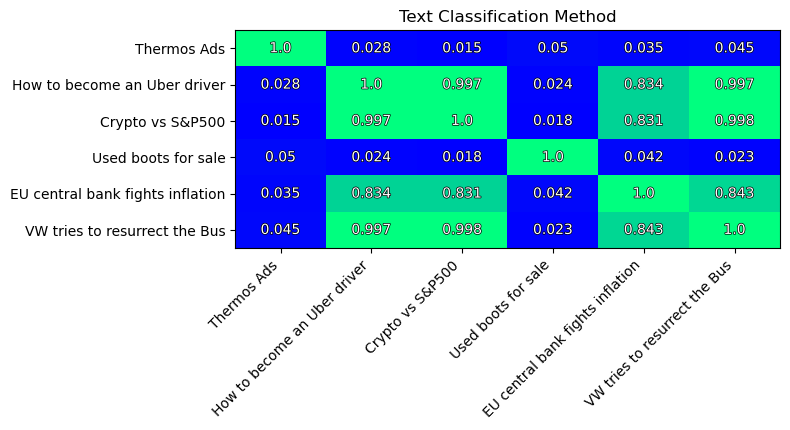
I like that similarities between embeddings have a wider range than those of previous methods. This means the method is able to capture some differences between texts. And thus we expect to have some better results in text comparison.
Yet, note the pair of most similar texts (similarity=0.998):
- “Crypto vs S&P500”
- “VW tries to resurrect the Bus”
This does not make any sense!
The simple negation test:
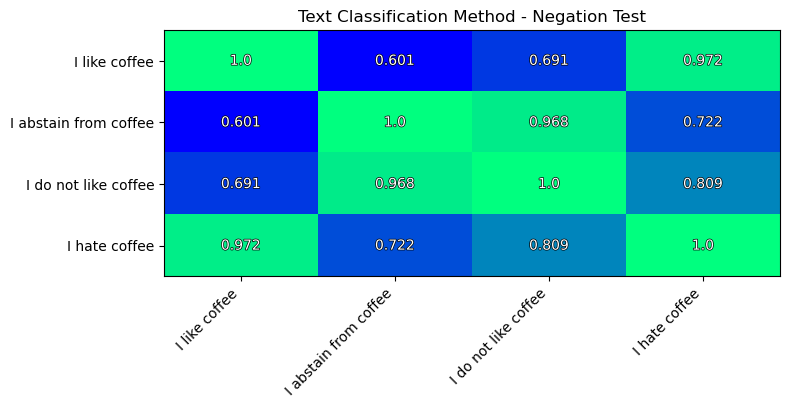
This method also fails the negation test. The I like coffee is most close to the I hate coffee.
This contradicts to our logic.
Pros and Cons
This approach has a great benefit as the text embedding is computed at one run, which is very fast.
The embeddings of this method are better suited for the task of texts comparison.
But it is almost impossible to find a pre-trained model which covers a wide range of categories. The 41 classes in the presented example, of course, are not enough to describe all variety of texts.
This implies you would need to train your own classifier. The only drawback of such approach is that in order to train such classifier, you need to construct a large enough dataset of texts with assigned categories labels.
Additionally, this method completely fails the simple negation test.
4. Sentence Transformers
Description
As it has been mentioned above, Word Embeddings method does not take into account the contextual relationships between words in a sentence. While in Text Classification method it is hard to define a comprehensive list of categories and train a model on it. If we take the best of both methods we end up with a Sentence Transformer method.
Here we use a BERT-based model, which is specially trained to produce text embeddings most suitable for comparison. The idea of how to train BERT-based networks for the task of text comparison was first described in the paper: Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks .
To achieve the best results for the task of semantic text similarity authors used the Triplet Objective Function.
Triplet Objective Function: Given an anchor sentence
a, a positive sentencep, and a negative sentencen, triplet loss tunes the model such that the distance betweenaembedding andpembedding is smaller than the distance betweenaembedding andnembedding.
This technique helped to gain the top scores in the task of comparison of texts.
Note, that we do not specify the list of categories manually, but let the training process to choose them automatically. Typically, existing pre-trained models produce embeddings of the size either 384 or 768 numbers.
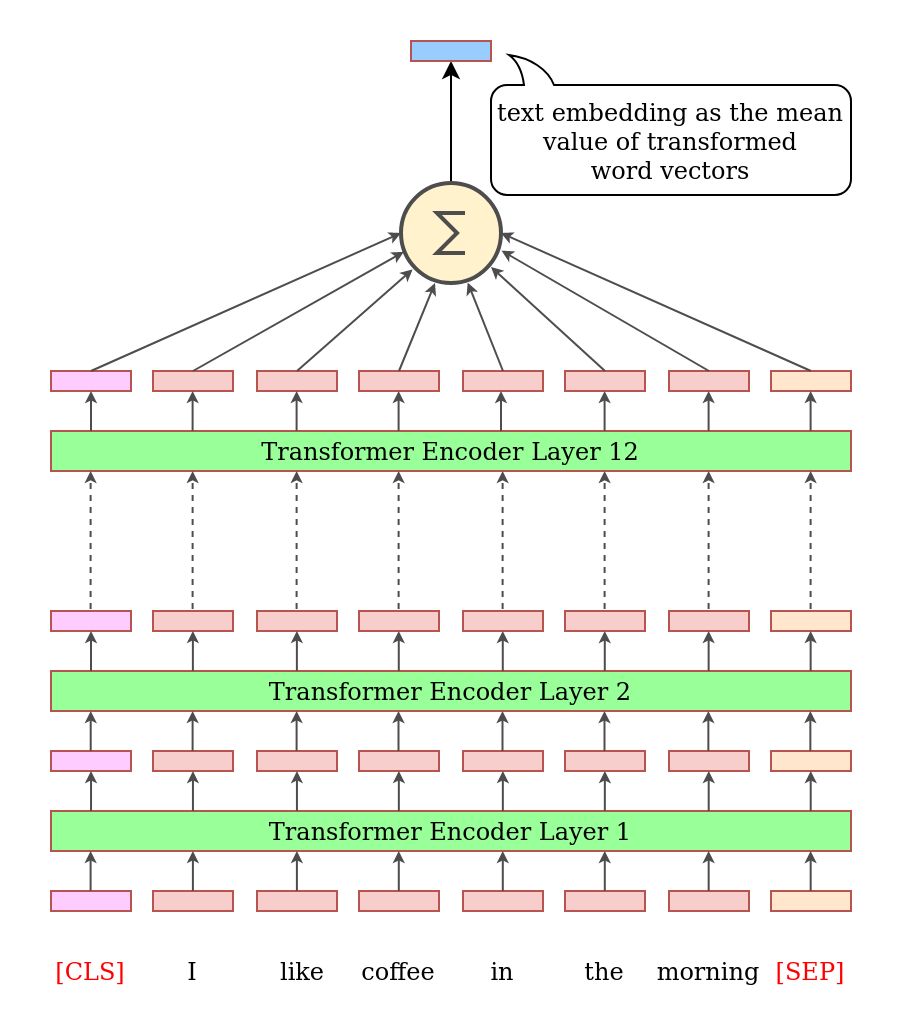
A text in such model is processed in multiple stages, similar to the Text Classification method:
- First text is tokenized (split into words or parts or words).
- Special tokens
[CLS]and[SEP]are added to the text. - Each token is substituted by corresponding token embedding using a pre-trained table.
- Those token embeddings are passed into the model.
- The information passes through multiple Transformer Encoder layers, and is transformed in each layer.
- As the output of a final layer we get transformed embeddings for each input word.
- Typically, we compute text embedding as the mean value of all output embeddings.
Computation
I am going to use the model sentence-transformers/all-mpnet-base-v2.
You need to install the sentence-transformers and scikit-learn Python libraries.
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
model_name = 'sentence-transformers/all-mpnet-base-v2'
model = SentenceTransformer(model_name)
texts = {
'Thermos Ads': 'Introducing the Adventure Thermos – your ideal companion for outdoor excursions! Engineered for durability and optimum insulation, this thermos keeps your beverages hot or cold in any terrain. Whether you’re hiking, camping, or simply enjoying the great outdoors, trust PeakPro to keep your drinks at the perfect temperature throughout your adventure. Upgrade your outdoor experience with the Adventure Thermos – where every sip is an exploration in refreshment.',
'How to become an Uber driver': 'Embark on a flexible and rewarding journey by becoming an Uber driver today! Getting started is easy – simply visit the Uber website or download the app to begin your driver application. Provide the required documents, including a valid driver’s license, insurance, and vehicle registration, and undergo a straightforward background check. Once approved, you’re ready to hit the road, set your own schedule, and earn money on your terms. Join the community of Uber drivers and turn your car into a source of income and independence.',
'Crypto vs S&P500': 'Amidst a correction in the S&P index, the cryptocurrency market remains remarkably stable, showcasing its resilience in the face of traditional market fluctuations. Investors find solace in the consistent performance of cryptocurrencies, highlighting their potential as a diversification strategy. As the S&P undergoes correction, the crypto market’s steadiness prompts a reevaluation of investment portfolios in the ever-evolving financial landscape.',
'Used boots for sale': 'For sale: Gently-used rubber boots in excellent condition! These reliable boots are ready for their next adventure, offering comfort and durability. Don’t miss the chance to snag a great pair at a fantastic price!',
'EU central bank fights inflation': 'In a bold move to tackle inflationary pressures, the European Union’s central bank has announced an increase in its key interest rate. This strategic measure aims to curb rising inflation and maintain economic stability within the EU. Investors and economists will closely monitor the impacts of this decision on financial markets and the broader economic landscape.',
'VW tries to resurrect the Bus': 'Volkswagen is making waves with the revival of the iconic VW Bus, now featuring a state-of-the-art electric engine. Combining nostalgia with environmental consciousness, the electric VW Bus aims to redefine road-tripping for the modern era. Get ready to experience the classic charm of the VW Bus with a sustainable twist, as Volkswagen pioneers a new chapter in electric mobility.',
}
embeddings = model.encode(list(texts.values()))
similarities = cosine_similarity(embeddings)
names = list(texts.keys())
plot_heatmap(similarities.round(3), title='Sentence Transformers Method', aspect=0.4, x_labels=names, y_labels=names, figsize=(8, 8))```
The similarity matrix of texts:
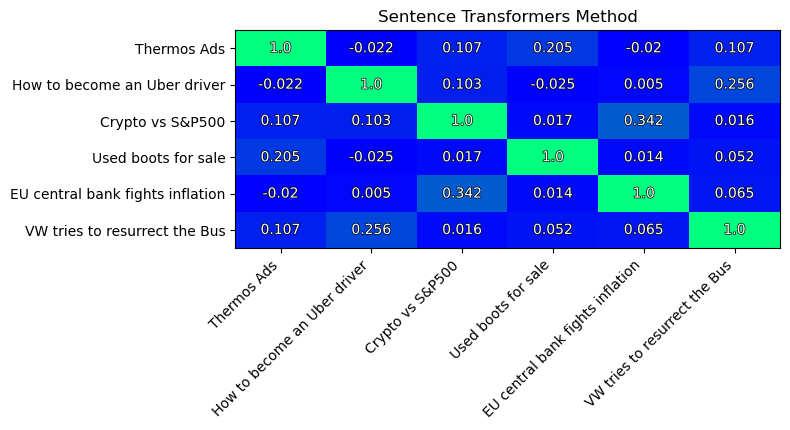
I like that similarities now have very wide range. This reflects that model is able to capture the semantic differences between texts very well.
Please, note that the two texts most close to each other (similarity=0.342) are:
- “Crypto vs S&P500”
- “EU central bank fights inflation”
The second pair of best matching texts is:
- “How to become an Uber driver”
- “VW tries to resurrect the Bus”
These results seem very reasonable!
The simple negation test:
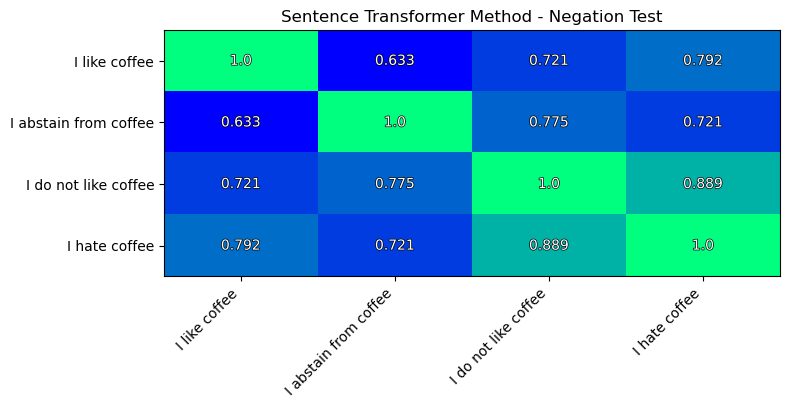
Well, this is better than in the previous methods.
But still: I hate coffee is closer to I like coffee, than to I abstain from coffee.
Pros and Cons
This approach has the advantage that the embedding vector is computed very fast, even without GPU (using CPU only).
The only disadvantage here is that these dimensions are hardly interpretable, like in the Words Embeddings method. I.e. we cannot know what is the meaning of the n-th dimension, what this number means for a particular text.
Nevertheless, we often do not need interpretability for the task of text comparison. All we need is the ability to compare different texts and measure their similarity.
The results of the simple negative test are better, but still not superior.
5. OpenAI Embeddings
Description
Nowadays, you no longer have to run models on your hardware. You can buy paid subscription and make computations using service provided by:
- OpenAI
- HuggingFace
- Microsoft Azure
- Google Cloud Platform,
- AWS SageMaker,
- etc.
Since OpenAI was the first company to present the state-of-the-art model in text generation: GPT-4, I want to show how to get text embeddings using the OpenAI API.
I am going to use the model: text-embedding-ada-002, which is described here:
OpenAI Blog - New and improved embedding model
Computation
You first need to install the openai and scikit-learn Python libraries.
import openai
from typing import Union, Sequence, List
from sklearn.metrics.pairwise import cosine_similarity
openai.api_key = 'PUT YOUR OPENAI KEY HERE'
texts = {
'Thermos Ads': 'Introducing the Adventure Thermos – your ideal companion for outdoor excursions! Engineered for durability and optimum insulation, this thermos keeps your beverages hot or cold in any terrain. Whether you’re hiking, camping, or simply enjoying the great outdoors, trust PeakPro to keep your drinks at the perfect temperature throughout your adventure. Upgrade your outdoor experience with the Adventure Thermos – where every sip is an exploration in refreshment.',
'How to become an Uber driver': 'Embark on a flexible and rewarding journey by becoming an Uber driver today! Getting started is easy – simply visit the Uber website or download the app to begin your driver application. Provide the required documents, including a valid driver’s license, insurance, and vehicle registration, and undergo a straightforward background check. Once approved, you’re ready to hit the road, set your own schedule, and earn money on your terms. Join the community of Uber drivers and turn your car into a source of income and independence.',
'Crypto vs S&P500': 'Amidst a correction in the S&P index, the cryptocurrency market remains remarkably stable, showcasing its resilience in the face of traditional market fluctuations. Investors find solace in the consistent performance of cryptocurrencies, highlighting their potential as a diversification strategy. As the S&P undergoes correction, the crypto market’s steadiness prompts a reevaluation of investment portfolios in the ever-evolving financial landscape.',
'Used boots for sale': 'For sale: Gently-used rubber boots in excellent condition! These reliable boots are ready for their next adventure, offering comfort and durability. Don’t miss the chance to snag a great pair at a fantastic price!',
'EU central bank fights inflation': 'In a bold move to tackle inflationary pressures, the European Union’s central bank has announced an increase in its key interest rate. This strategic measure aims to curb rising inflation and maintain economic stability within the EU. Investors and economists will closely monitor the impacts of this decision on financial markets and the broader economic landscape.',
'VW tries to resurrect the Bus': 'Volkswagen is making waves with the revival of the iconic VW Bus, now featuring a state-of-the-art electric engine. Combining nostalgia with environmental consciousness, the electric VW Bus aims to redefine road-tripping for the modern era. Get ready to experience the classic charm of the VW Bus with a sustainable twist, as Volkswagen pioneers a new chapter in electric mobility.',
}
def openai_embeddings(text: Union[str, Sequence[str]], model_name='text-embedding-ada-002') -> Union[List[float], List[List[float]]]:
"""Compute text embedding with OpenAI API"""
input_is_string = isinstance(text, str)
if input_is_string:
text = [text]
# Call API
response = openai.Embedding.create(
model=model_name,
input=text
)
# Extract the AI output embedding as a list of floats
result = []
for r in response.get('data', []):
result.append(r['embedding'])
if input_is_string:
return result[0]
return result
embeddings = openai_embeddings(list(texts.values()))
similarities = cosine_similarity(embeddings)
names = list(texts.keys())
plot_heatmap(similarities.round(3), title='Sentence Transformers Method', aspect=0.4, x_labels=names, y_labels=names, figsize=(8, 8))
The similarity matrix of texts:
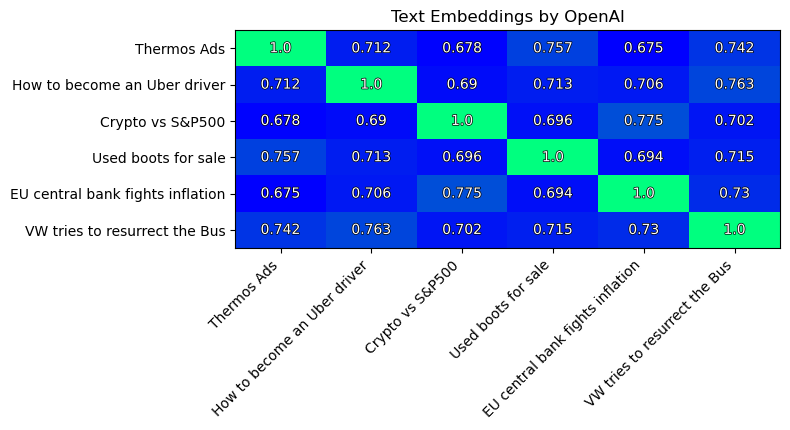
Note the pair of most similar texts (similarity=0.775):
- “Crypto vs S&P500”
- “EU central bank fights inflation”
On the second place we have a pair of two texts (similarity=0.763):
- “How to become an Uber driver”
- “VW tries to resurrect the Bus”
These results are expected.
Yet, I do not like that the similarities range is not as wide as in the Sentence Transformers method. But it is better than of the first three methods.
The simple negation test:
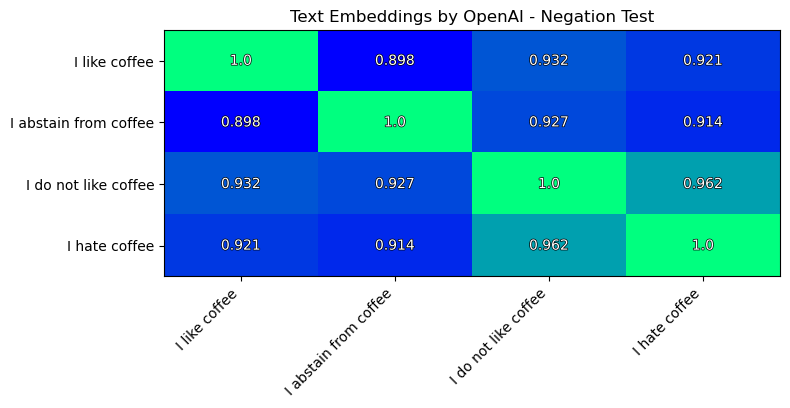
Well, this is not awful, but still not perfect.
I like coffee is closer to I hate coffee, than to I abstain from coffee.
Pros and Cons
According to some sources: 1, 2 - embeddings produced by OpenAI are not very good for the task of text comparison.
OpenAI does not disclose the details of how the model text-embedding-ada-002 has been trained,
what was the training dataset and loss function.
There is a special benchmark to compare the performance of different models on the task of text comparison:
benchmark.
Unfortunately, there is no result for the latest OpenAI model text-embedding-ada-002.
In the resulting similarities matrix I can see that similarities are still quite high: ~0.7. I would suggest the model did not grasp the differences between texts well enough.
Additionally, the results of the simple negation test are not impressive.
The individual dimensions of OpenAI embeddings are also not interpretable, like in the Words Embeddings and Sentence Transformer methods.
The only benefit I can see in using this method is that you do not need any decent hardware. You can simply buy (comparably) cheap subscription and proceed with it.
Dealing With Long Texts
Most of attention-based models have limitation of only 512 input tokens. Because self-attention approach has a quadratic complexity O(n²) in terms of the sequence length n. This is roughly equivalent to nearly 200 words.

Typical approaches are:
- Use only one part of a text to compute embeddings (first, middle or last).
- Split text into chunks, process each of them individually and combine the results back together.
- Use chunks (as in option 2) but feed the output token for each chunk to another network to produce the final result.
Processing Long Texts by Chunks looks like this:

Navigate to other articles of the series
- Text Embeddings (1/3) - Explanation
- Text Embeddings (2/3) - Computation (you are here)
- Text Embeddings (3/3) - Conclusion