
Text Embeddings (1/3) - Explanation
Introduction
This is “yet another explanation of text embeddings for beginners”.
Sometimes I have to explain potential clients the concept of text embeddings. That is why I have created this article.
This is the first of three articles on text embeddings for beginners:
- Text Embeddings (1/3): Explanation (you are here)
- Text Embeddings (2/3): Computation
- Text Embeddings (3/3): Conclusion
What is the Problem of Comparing Texts?
Almost anyone can easily compare texts. But when you need to process and compare many texts - you may want to use a machine for this task.
The task of comparing texts often arises in many areas. Just a few examples:
- You need to recognize user interests by studying the webpages, he visited. This is to find out if user might be interested in a certain product or services, for the task of online advertisement.
- Given some user query you need to find relevant documents in your database. This is when you build a search tool over some knowledge base.
- You are building a recommendation system and need to compare descriptions of products or services (or movies). Using a vector representation simplified the task.
Working with raw texts is not very practical if you need to process and compare them programmatically:
- They can be of arbitrary lengths.
- Words can have different meaning depending on the context.
- Two different phrases can mean the same.
From Text to Numbers
It would be great is we could represent a text with a number, because we can easily compare two numbers.
But a single number is not enough! Imagine, you need to assign a single number to a book. What meaning would you choose for it? A price? A rating?
A single number can not describe:
- Is it a fantasy, a science fiction, a romance book, …?
- What is the book’s rating among different categories of readers?
- How many characters are there?
- Is the ending of the book negative or positive?
- etc.
In order for machine to compare two books, for example, it may require you to describe them with quite a lot of numbers:

This is how we came up with the idea to assign a list of numbers to describe a text.
Note: It is important to understand, that no matter how long or short a text is the size of list of numbers must always be the same.
But before we dive into that I would like first to describe the long journey of textual analysis that has led us to this point.
Long History of Text Analysis. Briefly.
The history of text analysis, especially in the comparison of two texts, has been evolving over many years, starting from simple statistical approaches to more sophisticated techniques like text embeddings.
-
19th Century: Word Frequency Analysis: One of the earliest forms of text analysis based on counting word frequencies.
-
1960s: Key Word in Context (KWIC): With the advent of computers, researchers developed tools like KWIC to analyze concordances, displaying words in context. This helped in understanding how words were used within a given text.
-
1960s - 1970s: Vector Space Models (VSM): Represented documents as vectors in a high-dimensional space based on term frequencies. Term Frequency-Inverse Document Frequency (TF-IDF) is the most well-known example of such method. It measures the importance of terms in a document relative to importance of these terms in a corpus.
-
1980s - 1990s: Latent Semantic Analysis (LSA): Introduced the concept of capturing latent semantic relationships between terms. It uses Singular Value Decomposition (SVD) algorithm to reduce the dimensionality of the term-document matrix, enabling the discovery of hidden relationships between words.
-
Late 20th Century - Early 21st Century: Machine Learning Approaches: Algorithms like Naive Bayes, Support Vector Machines (SVM), and k-means clustering were applied to compare and analyze texts based on their content.
-
2010 - 2018: Word Embeddings and Neural Networks: Algorithms like Word2Vec and GloVe, represented words as dense vectors in a continuous vector space, capturing semantic relationships. This allowed for more nuanced text comparisons. Combined with neural network architectures like Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs) they became popular for processing texts, language translation, etc.
-
2018 - now: Transformer architectures: After the paper Attention Is All You Need there is an ongoing blossom of models for text semantic processing and text generation. These models use attention mechanisms to capture contextual relationships between words. It revolutionized natural language processing tasks, including text comparison, by considering the entire context of a word within a sentence.
Text Embeddings Step-by-Step
Now I’m going to walk you through the idea of how to represent a text (of arbitrary length) as a list of numbers (of fixed length).
Sample Texts
Here are six texts to be used throughout this article. I tried to make them as short as possible, because… well, nobody likes long texts nowadays.
Thermos Ads

Expand text
Introducing the Adventure Thermos – your ideal companion for outdoor excursions! Engineered for durability and optimum insulation, this thermos keeps your beverages hot or cold in any terrain. Whether you're hiking, camping, or simply enjoying the great outdoors, trust PeakPro to keep your drinks at the perfect temperature throughout your adventure. Upgrade your outdoor experience with the Adventure Thermos – where every sip is an exploration in refreshment.How to become an Uber driver

Expand text
Embark on a flexible and rewarding journey by becoming an Uber driver today! Getting started is easy – simply visit the Uber website or download the app to begin your driver application. Provide the required documents, including a valid driver's license, insurance, and vehicle registration, and undergo a straightforward background check. Once approved, you're ready to hit the road, set your own schedule, and earn money on your terms. Join the community of Uber drivers and turn your car into a source of income and independence.Crypto vs S&P500

Expand text
Amidst a correction in the S&P index, the cryptocurrency market remains remarkably stable, showcasing its resilience in the face of traditional market fluctuations. Investors find solace in the consistent performance of cryptocurrencies, highlighting their potential as a diversification strategy. As the S&P undergoes correction, the crypto market's steadiness prompts a reevaluation of investment portfolios in the ever-evolving financial landscape.Used boots for sale

Expand text
For sale: Gently-used rubber boots in excellent condition! These reliable boots are ready for their next adventure, offering comfort and durability. Don't miss the chance to snag a great pair at a fantastic price!EU central bank fights inflation

Expand text
In a bold move to tackle inflationary pressures, the European Union's central bank has announced an increase in its key interest rate. This strategic measure aims to curb rising inflation and maintain economic stability within the EU. Investors and economists will closely monitor the impacts of this decision on financial markets and the broader economic landscape.VW tries to resurrect the Bus

Expand text
Volkswagen is making waves with the revival of the iconic VW Bus, now featuring a state-of-the-art electric engine. Combining nostalgia with environmental consciousness, the electric VW Bus aims to redefine road-tripping for the modern era. Get ready to experience the classic charm of the VW Bus with a sustainable twist, as Volkswagen pioneers a new chapter in electric mobility.Measure one dimension: Physical product vs. Service
First we can start by “measuring” how each of these texts is related to Physical Product vs Service. Where:
- -1 means: a text is about a physical product,
- 0 means: text is not about a physical product or service,
- 1 means: text is about a service.
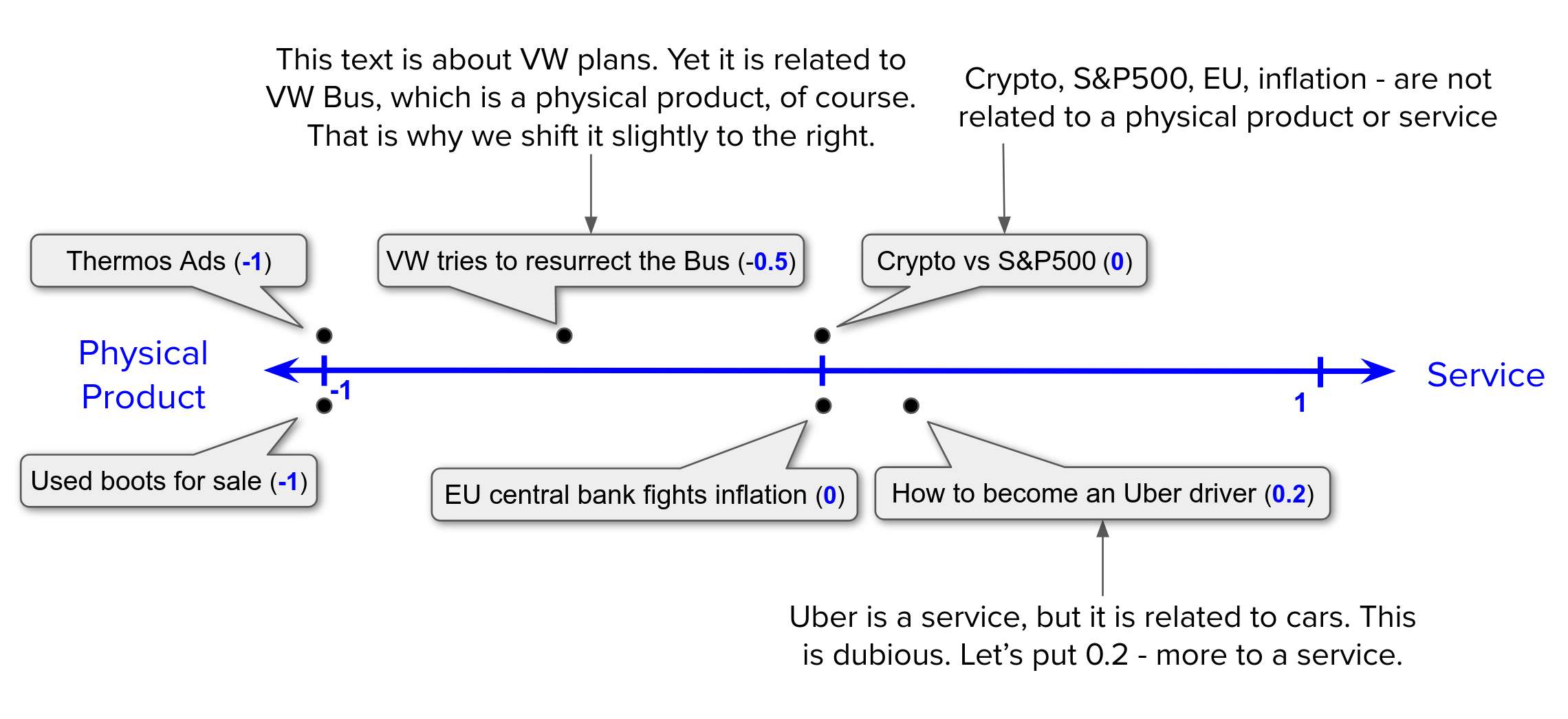
Note: it is sometimes hard to explicitly tell a text is about a product or a service!
Add another dimension: Relation to Travel
Then we can add another dimension: Relation of a text to Travel, where:
- -1 means: a text is not related to travelling,
- 0 means: it is hard to tell,
- 1 means: text is related to travelling.
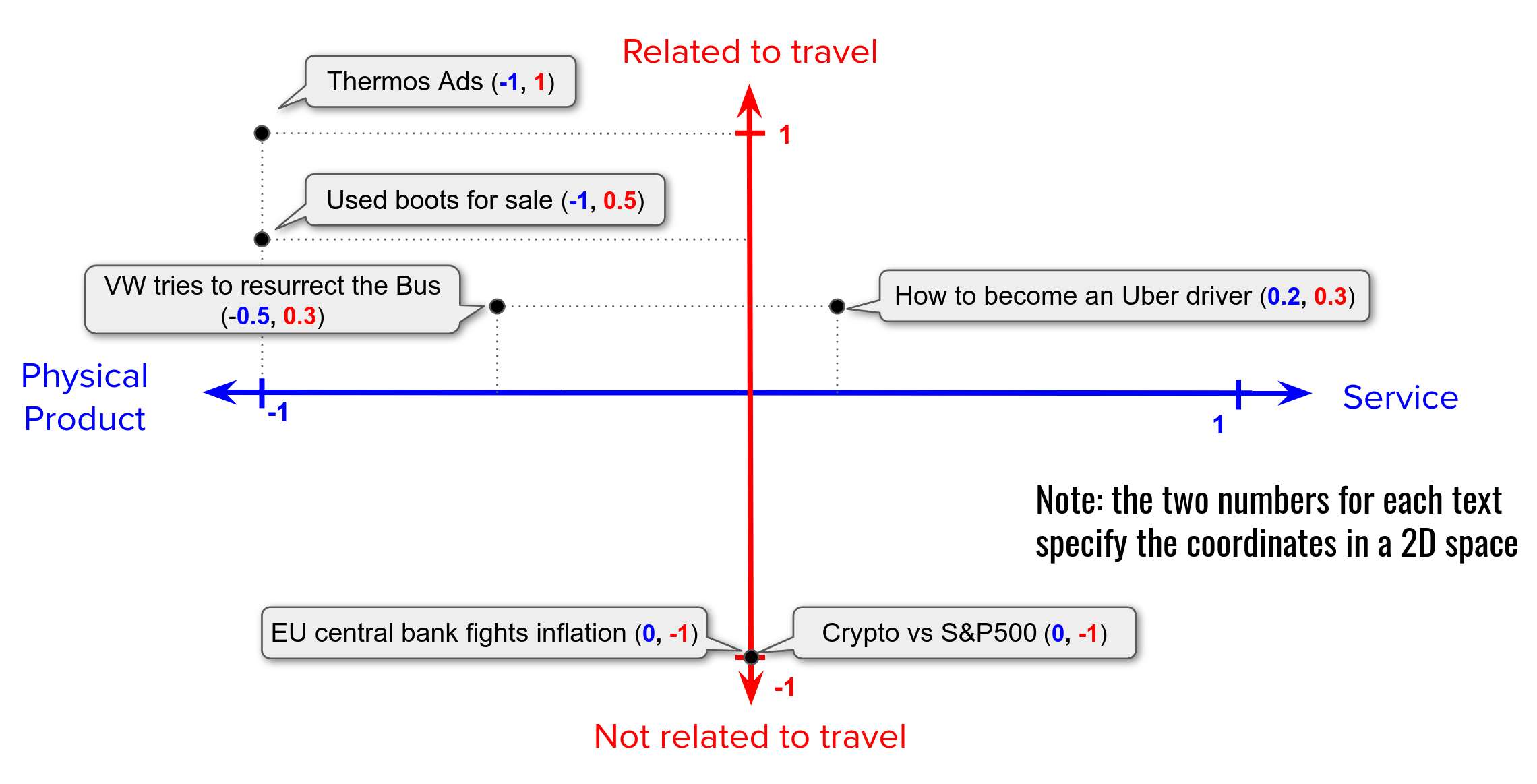
Add many more dimensions
Then we can add many more dimensions:
- Relation to Finance
- Relation to News
- etc.
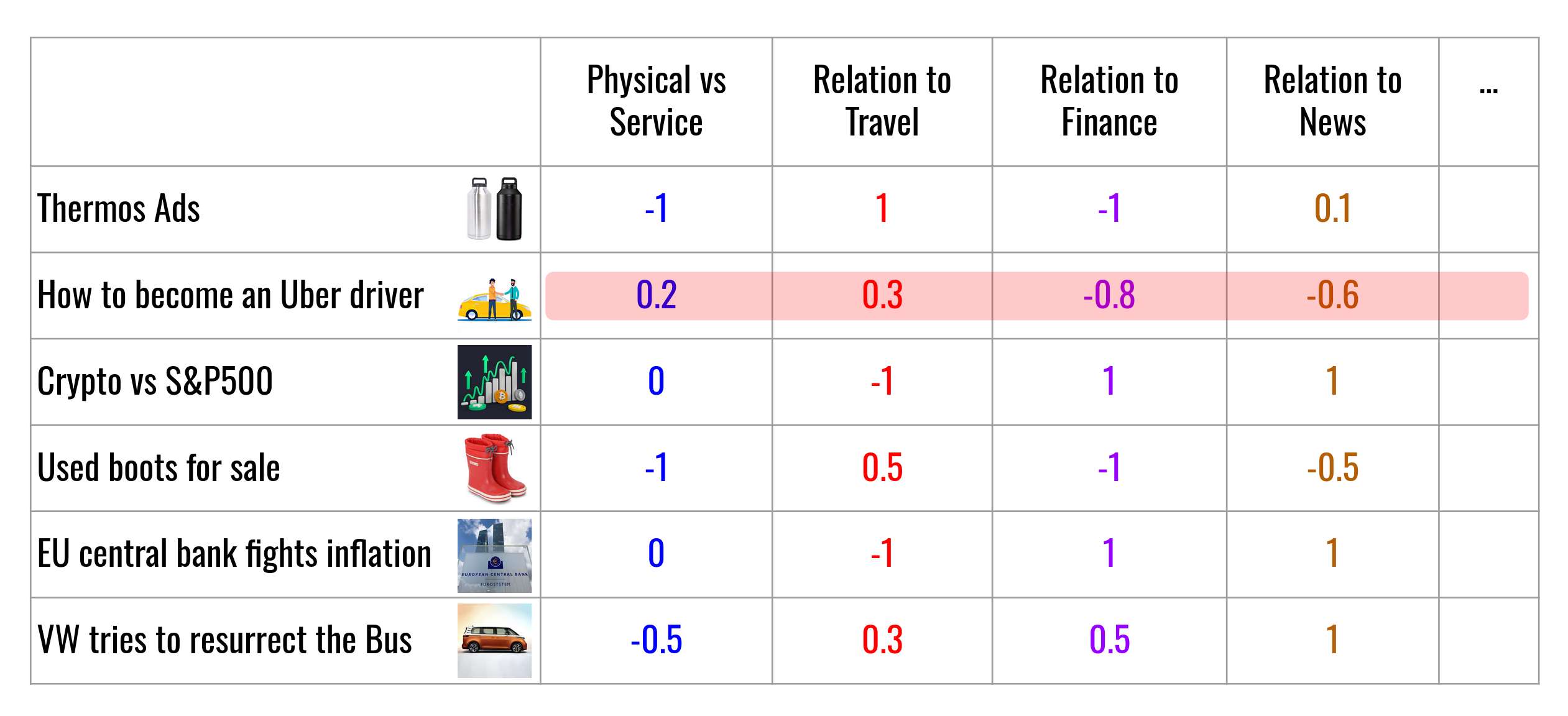
Now for each text we get a list of N numbers. It is called: text embedding.
This list defines the coordinates of a text in N-dimensional space. Texts with related content are located nearby in this space.
How to choose dimensions?
In the examples above we have specified the meaning of dimensions manually:
- Physical vs Service
- Relation to Travel
- Relation to Finance
- Relation to News
- etc.
While in practice we allow a computer program to choose the meaning of the coordinate axes algorithmically. The semantic space we obtain in this way is better suited for our purpose: to determine whether two texts are similar or not. (See: Sentence Transformers).
Euclidean vs Cosine Distances
Now that we have computed the vector embeddings for all texts, we can measure the distance between them to compare their similarity.
We are used to understanding the distance as the Euclidean Distance. Meanwhile, there are many other measures which can be computed of two vectors.
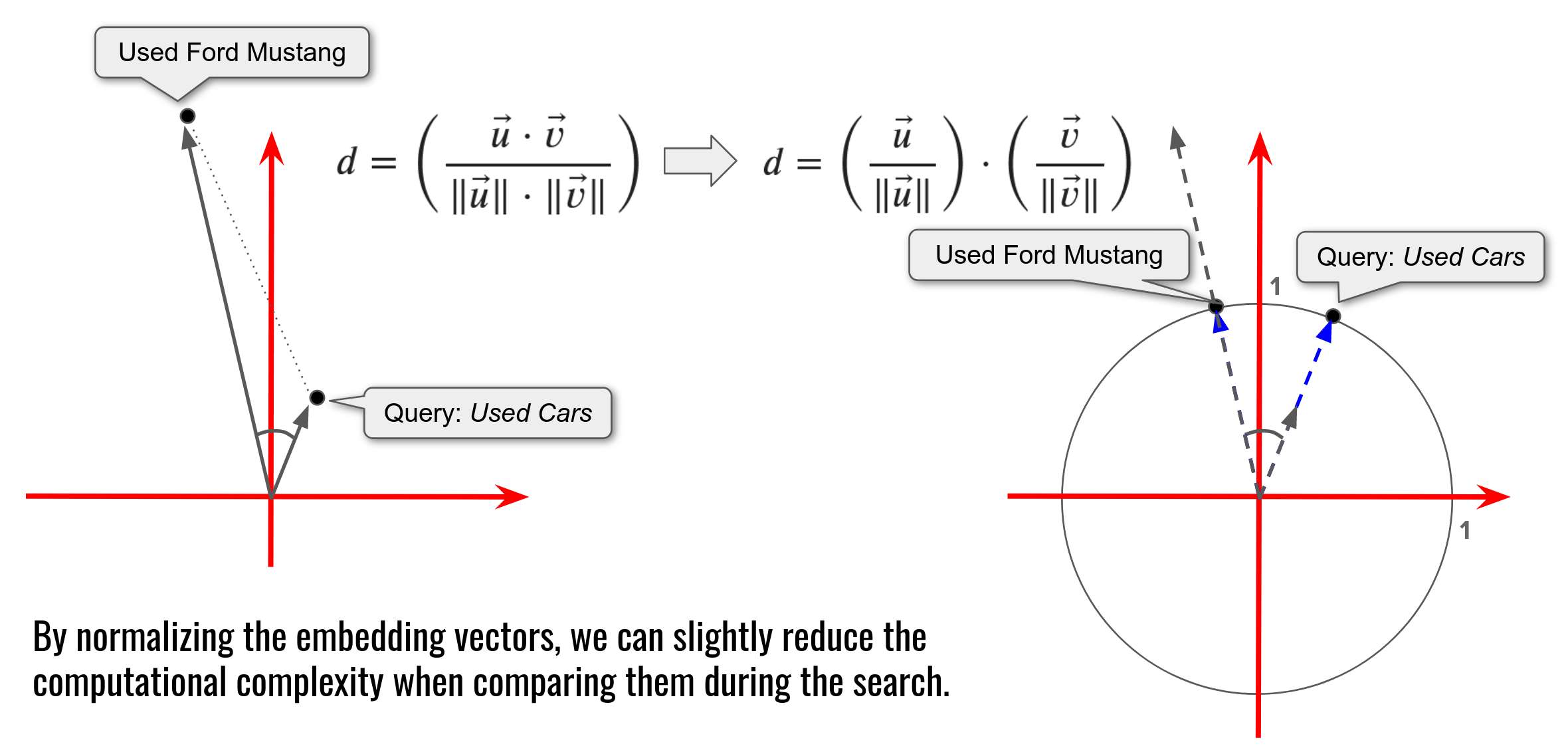
In fact, for the task of text-embedding comparison the Cosine Similarity measure is more appropriate.
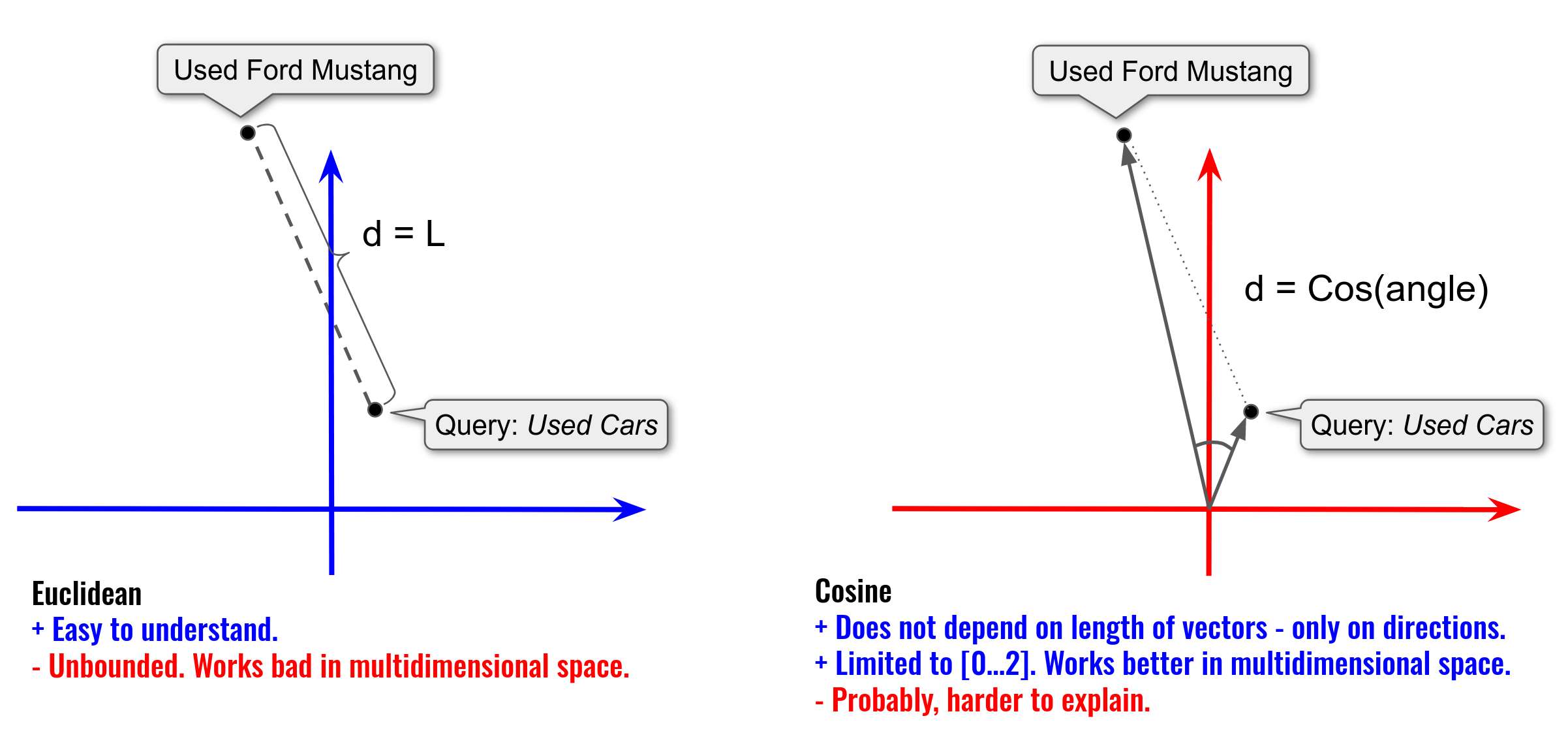
From Cosine Distance to Dot Product
One minor addition here is the fact, that when using the cosine similarity, it is better to keep embedding vectors normalized (to the unit length). As this measure does not depend on the length of vectors, but only on their directions. This helps to slightly decrease the computations when working with a large amount of embeddings.
Navigate to other articles of the series
- Text Embeddings (1/3): Explanation (you are here)
- Text Embeddings (2/3): Computation
- Text Embeddings (3/3): Conclusion